Pipeline con datos particionados¶
El dataset a menudo lo integran múltiples archivos almacenados en particiones del sistema de ficheros en el dispositivo de almacenamiento. PyArrow es la librería Python para la integración de la implementación C++ de Apache Arrow que proporciona un formato de memoria columnar de alto rendimiento para un intercambio de datos rápido y sin copias (Zero-Copy IO), sólo buffers Arrow. A diferencia de los enfoques convencionales que requieren múltiples copias de datos durante las transferencias, Arrow mantiene los datos en su formato columnar a lo largo de todo el proceso. Esto significa que los datos se mueven entre actividades sin la sobrecarga de los ciclos de serialización/deserialización, lo que reduce drásticamente el uso de CPU y la demanda de memoria. Provee una integración perfecta con pandas, NumPy y varios formatos de archivo (Parquet, CSV). Este ejemplo introductorio invoca a la función pyarrow.dataset.dataset() para leer todos los archivos y presentarlos en un resultado único
NYC Taxi Dataset
1. Scan Parquet como tabla Arrow¶
PyArrow Tabular Datasets
El siguiente código muestra la lectura de datos en formato Parquet particionado utilizando un pyarrow.dataset
import duckdb
import pyarrow as pa
import pyarrow.dataset as ds
# Explicitar las columnas relevantes
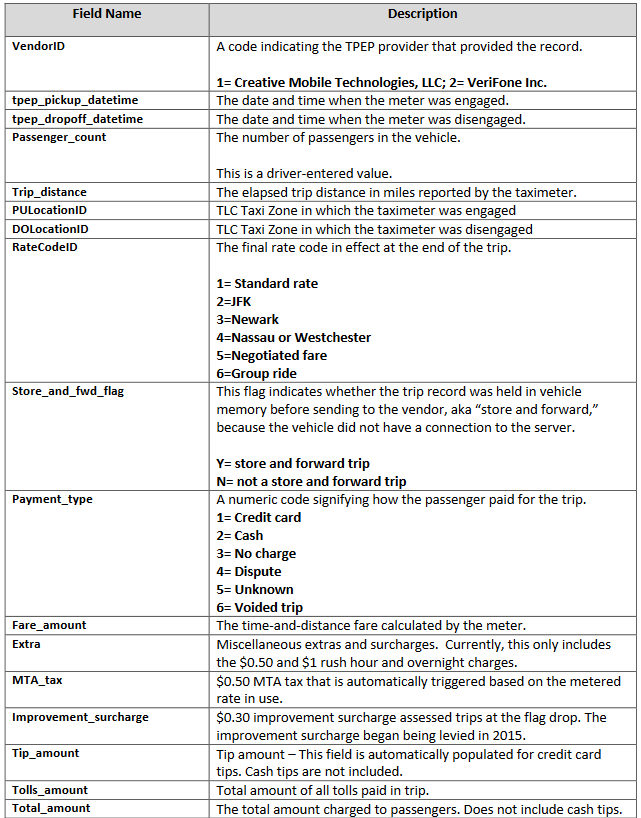
working_columns = ["VendorID","tpep_pickup_datetime","tpep_dropoff_datetime","passenger_count",
"trip_distance","RatecodeID","store_and_fwd_flag","PULocationID","DOLocationID","payment_type",
"fare_amount","extra","mta_tax","tip_amount","tolls_amount","total_amount","w", "d"]
# Acceso a los datos particionados
nyc_ds = ds.dataset('Parquet/', partitioning=["w", "d"])
# Scanner sobre las columnas establecidas
ds_scanner = nyc_ds.scanner(columns=working_columns)
# Materializar el dataset resultante como tabla Arrow
# Lazy eval, sin copias, sin objetos Python en memoria
nyc_table = ds_scanner.to_table()
Muestreo Pandas (Opcional)¶
# Convertir tabla Arrow en Pandas Dataframe
nyc_df = nyc_table.to_pandas()
# Filtrar datos en Pandas Dataframe
filtro = nyc_df[(nyc_df.total_amount > 100) & (nyc_df.w == "w=17")]
# Seleccionar columnas (proyección vertical)
res = filtro[["d","total_amount", "passenger_count"]]
res.head(25)
2. Consulta DuckDB directa a los datos en la tabla Arrow, sin copias¶
La integración de Arrow en DuckDB permite consultar los datos en la tabla directamente, sin intermediarios 💪💪
con = duckdb.connect()
con.register("arrow_t", nyc_table) # zero-copy registration
res = con.execute("""
SELECT w, d, VendorID, tpep_pickup_datetime, tpep_dropoff_datetime,
passenger_count, trip_distance, total_amount
FROM arrow_t
WHERE (total_amount > 100) AND (w LIKE 'w=17')
LIMIT 10
""").fetch_arrow_table() # retorno Arrow, sigue zero-copy
# Print res como DuckDB relation
con.from_arrow(res).show
# Siempre, siempre, siempre cerrar las conexiones
con.close()