DataFrames
Un DataFrame es una estructura que organiza los datos en una tabla bidimensional de filas y columnas, muy similar a una hoja de cálculo o a una tabla relacional. Su importancia radica en que son una de las estructuras de datos más comunes utilizadas en los pipelines que proveen el análisis de datos moderno ya que constituyen una forma muy flexible e intuitiva de almacenar y trabajar con datos
Cada DataFrame contiene un plano de metadatos, conocido como esquema, que define el nombre y el tipo de datos de cada columna. El concepto de DataFrame es común en muchos lenguajes y entornos diferentes. Los DataFrames pueden contener tipos de datos universales como StringType e IntegerType así como tipos de datos específicos como, por ejemplo, StructType en Spark. Los valores que faltan o están incompletos se almacenan como valores nulos en el DataFrame
Python Dataframes¶
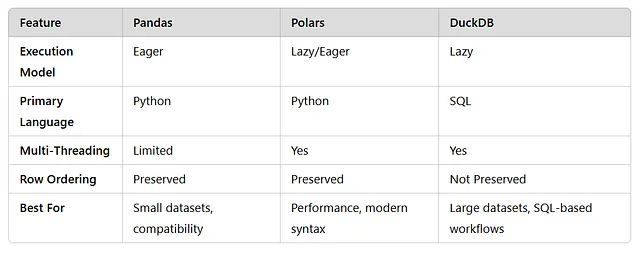
En Python los DataFrames Pandas, para muchos la herramienta que lo inició todo, son el principal tipo de datos utilizado pero no son exclusivos de Python sino que también se utilizan en otros lenguajes como, por ejemplo, R o Scala. Con el paso de los años, se ha convertido en sinónimo de manipulación y exploración de datos, ofreciendo flexibilidad, bibliotecas específicas para cada dominio y un ecosistema sin igual. Sin embargo, a medida que crece el volumen de los datos y cambian las exigencias de rendimiento, han surgido nuevas herramientas que desafían su dominio, cada una de ellas con sus propias ventajas
Polars Dataframe, Apache Arrow, DuckDB¶
Polars y DuckDB (ver labs Pandas vs Polars vs DuckDB, Lazy Eval y Arrow + DuckDB) son dos de estas herramientas, cada una diseñada para resolver puntos débiles específicos con los que Pandas presenta dificultades. Ya sea para manejar conjuntos de datos masivos de manera más eficiente, optimizar el rendimiento de las consultas o introducir una sintaxis innovadora, estas herramientas ofrecen nuevas y emocionantes posibilidades (modelo mental) para los profesionales de los datos. Sin embargo, elegir la herramienta adecuada no siempre es sencillo. Cada una tiene su curva de aprendizaje, sus ventajas e inconvenientes y sus escenarios de uso ideales. Polars introduce una nueva sintaxis diseñada para ofrecer flexibilidad y rendimiento, mientras que DuckDB reinventa el SQL para los flujos de trabajo analíticos modernos
Polars: "DataFrames for the new era"¶
Polars se ha diseñado desde cero pensando en el rendimiento. Se ha construído sobre la base de Apache Arrow, el cual en realidad no es una librería sino un formato de datos, que proporciona:
- Manejo eficiente de la memoria y compatibilidad con otras herramientas basadas en Arrow
- Simplifica el trabajo con bibliotecas externas y garantiza operaciones sin copias, lo que reduce la sobrecarga al pasar de una herramienta a otra
- Intrínsecamente multihilo, lo que le permite utilizar eficazmente los modernos procesadores multinúcleo
A diferencia de Pandas, que procesa todas las operaciones de forma inmediata (ejecución inmediata), Polars admite tanto ejecución inmediata como diferida. La ejecución diferida (Lazy Evaluation) permite a Polars DataFrame optimizar las operaciones antes de ejecutarlas, lo que reduce el uso de memoria y mejora la eficiencia. En cierto modo, es la estrategia de los optimizadores relacionales fuera del ecosistema relacional
Otra característica destacada de Polars es su capacidad para manejar de forma inteligente las operaciones con datos ordenados. Una vez que se ordenan los datos, Polars recuerda el orden, lo que permite operaciones posteriores más rápidas. También destaca en las funciones de ventana, que son rápidas e intuitivas de implementar
La disponibilidad de estas nuevas herramientas es esencial para muchos profesionales de los datos. Anteriormente, el manejo de grandes conjuntos de datos podía requerir hardware especializado o clústeres. Con DuckDB y Polars, conjuntos de datos que antes bloqueaban las máquinas más potentes ahora se pueden procesar de manera eficiente incluso en ordenadores portátiles
| DataFrames: Polars + DuckDB | |
|---|---|
| El enfoque moderno del DataFrame se representa mágico en la metáfora de unas gafas con código reflejado en los cristales. La imagen evoca innovación, claridad y una visión de futuro para el análisis de datos |  |
A medida que la infraestructura de datos de las organizaciones crece demanda herramientas más potentes y, sobre todo, adaptables. Ello permite resolver problemas más grandes con menos limitaciones. Al experimentar, aprender e integrar estas herramientas en los flujos de trabajo, no solo significa mantenerse actualizado en la evolución de la ingeniería de datos, sino que también ayuda a dar forma a su futuro. Esta capacidad de integrar herramientas a la perfección garantiza que los usuarios puedan adaptar sus flujos de trabajo a medida que evolucionan sus necesidades