SQL avanzado
Esta entrada repasa algunas de las técnicas avanzadas que incorpora la práctica totalidad de los gestores modernos
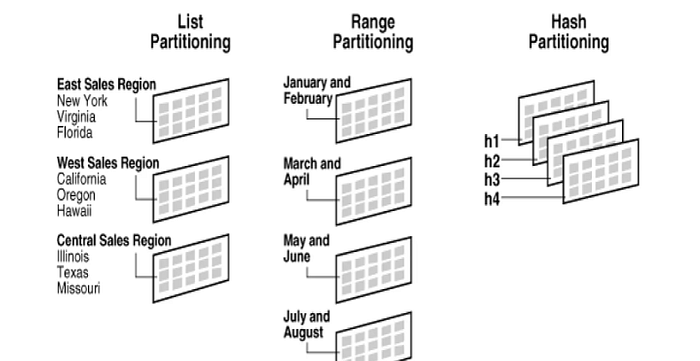
Particionado de Datos¶
Consiste en dividir una tabla en partes lógicas denominadas particiones. Básicamente, hay cuatro tipos de particionado:
- Partición por lista: este es el método que podemos utilizar cuando queremos dividir la tabla en particiones separadas según los valores de una columna determinada. Se utiliza en casos en los que los datos se pueden clasificar, como el nombre del producto, el país o la ciudad
- Partición por rango: se utiliza para dividir la tabla según fechas o números específicos
- Partición hash: al particionar datos, se puede utilizar para distribuir los valores de una columna determinada entre las particiones de forma equilibrada pero aleatoria, pasándolos por una función hash. Interesante si se desea distribuir los datos de forma equitativa
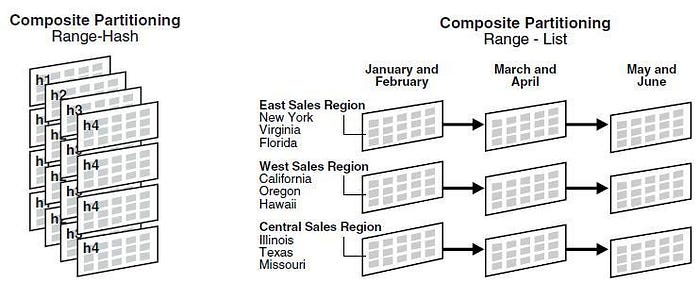
- Partición compuesta: las particiones creadas mediante una combinación de los métodos de partición anteriores se denominan particiones compuestas
| Particionado básico | Particionado mixto |
|---|---|
 |  |
VIEWs¶
Simplifican consultas complejas recopilando las tablas SQL deseadas en una tabla virtual como si fuera una tabla real
CREATE VIEW sales_team_info AS
SELECT
employees.employee_id,
employees.first_name,
employees.last_name,
employees.email,
employees.phone_number,
departments.department_name,
sales.total_sales,
sales.region
FROM
employees
INNER JOIN departments ON employees.department_id = departments.department_id
INNER JOIN sales ON employees.employee_id = sales.employee_idWHERE departments.department_name='Sales';
Transacciones MVCC: COMMIT, ROLLBACK¶
Se utiliza el control de concurrencia multiversión (MVCC) para controlar el acceso a los datos de una base de datos. Este sistema de control permite que se produzcan múltiples transacciones en la base de datos al mismo tiempo y garantiza la coherencia de los datos. El MVCC se desarrolló para permitir que las operaciones de lectura y escritura simultáneas se realizaran de forma coherente y sin interferir entre sí
BEGIN;
INSERT INTO games (name, genre, release_of_date, price)
VALUES ('The Last of Us Part II', 'Action', '2020-06-19', 59.99);
UPDATE games
SET price = 49.99
WHERE title = 'The Last of Us Part II';
DELETE FROM games WHERE id = 99999;
COMMIT;
ROLLBACK;
Estructuras de control de programa: IF, CASE¶
Importante notar que con este tipo de operaciones el SQL pierde su carácter puramente declarativo
Ejemplo CASE¶
| Ejemplo 1 | Ejemplo 2 |
|---|---|
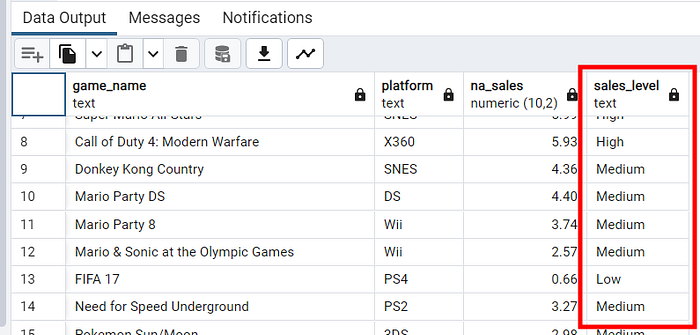 |  |
SELECT game_name, Platform, NA_Sales,
CASE
WHEN NA_Sales > 5 THEN 'High'
WHEN NA_Sales BETWEEN 2 AND 5 THEN 'Medium'
ELSE 'Low'
END AS Sales_Level
FROM video_games;
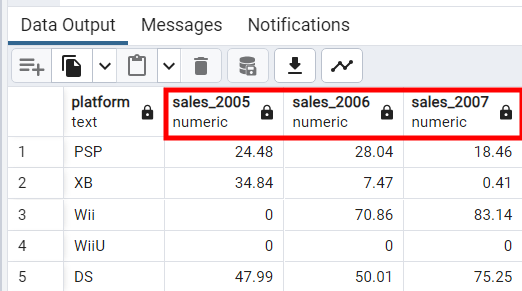
SELECT
platform,
SUM(CASE WHEN year_of_release = 2005 THEN NA_Sales ELSE 0 END) AS sales_2005,
SUM(CASE WHEN year_of_release = 2006 THEN NA_Sales ELSE 0 END) AS sales_2006,
SUM(CASE WHEN year_of_release = 2007 THEN NA_Sales ELSE 0 END) AS sales_2007
FROM
video_games
GROUP BY
platform;
Triggers, Functions, UDFs, Procedures¶
DDL¶
CREATE OR REPLACE FUNCTION set_created_at()
RETURNS TRIGGER AS $$
BEGIN NEW.created_at := NOW();
RETURN NEW;
END;
CREATE TRIGGER before_insert_videogame
BEFORE INSERT ON video_games
FOR EACH ROW
EXECUTE FUNCTION set_created_at();
DML¶
INSERT INTO video_games (game_name, platform, year_of_release, genre, publisher, na_sales, eu_sales, jp_sales, other_sales, global_sales)
VALUES ('Galactic Conquest', 'PS5', 2024, 'Sci-Fi RPG', 'FutureTech Games', 1.20, 0.95, 0.30, 0.10, 2.55);
Resultado¶

Otros Temas¶
Indexación¶
Cuando trabajamos con una base de datos grande y necesitamos encontrar un dato, la máquina buscará en cada fila hasta encontrarlo. Si las búsquedas fueran únicamente secuenciales y los datos que busca se encuentran hacia el final, esta consulta tardará mucho tiempo en ejecutarse. Un índice permite eliminar este problema. En general, se trata de reducir los tiempos de procesamiento de las consultas
Delicatessen de Markus Winand y en español 😳😳
DDL¶
CREATE INDEX idx_name
ON employees (first_name, last_name);
DML¶
SELECT *
FROM employees
WHERE first_name= 'ESRA';
Tablas temporales¶
Las tablas temporales son las que solo existen durante una transacción o sesión determinada y se eliminan automáticamente cuando finaliza la sesión. Las tablas temporales se utilizan a menudo para almacenar datos temporales, realizar operaciones de cálculo intermedias o conservar datos temporalmente entre operaciones de base de datos
DDL¶
CREATE TEMPORARY TABLE temp_employees (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50)
);
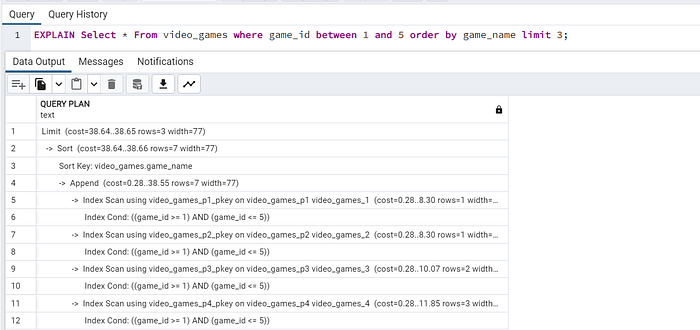
EXPLAIN: Query Plan¶
Explain (Documentación MySQL) permite obtener información del plan de ejecución antes o durante el proceso de ejecución de una consulta en aras de optimizar la orden SQL que ejecutaremos. Dependiendo de la complejidad de la consulta, proporciona información sobre temas como la estrategia de join, el método de extracción de datos de las tablas y las filas estimadas utilizadas para ejecutar la consulta
SQL¶
EXPLAIN Select * from video_games where game_id between 1 and 5 order by game_name limit 3;
Resultado¶