Modern Data Stack: Data Pipelines, ETLs, Data Warehousing¶
En 1970, Edgar F. Codd revolucionó el campo de la gestión de datos con la invención del álgebra relacional, un concepto basado en una sólida base teórica. Este avance condujo al desarrollo de las bases de datos relacionales y el lenguaje SQL que han sido indiscutiblemente dominantes para el procesamiento de datos durante más de cincuenta años
Expertos de renombre como C.J. Date y Hugh Darwen defendieron durante años que las bases de datos relacionales podían, en teoría, gestionar una amplia gama de cargas de datos. Sin embargo, las bases de datos relacionales existentes tenían deficiencias específicas que evidenciaban la necesidad de otro tipo de solución
Las arquitecturas de datos modernas como data lakehouses, data hubs, data fabrics, etc. carecen de un marco teórico cohesionado y contrastado como el modelo relacional y tampoco abordan de manera eficaz la totalidad de los retos que plantean los datos en la actualidad. Los debates sobre las diferencias entre estas arquitecturas pueden volverse excesivamente académicos, recordando a los debates medievales sobre conceptos abstractos como el número de ángeles que cabrían en la cabeza de un alfiler 🤯🤯. Esta situación pone de relieve la necesidad de principios arquitectónicos fundamentales que permitan diferenciar claramente una arquitectura de otra. Aunque estas arquitecturas modernas ofrecen herramientas valiosas, sigue siendo necesario algo más radical y fundamental
Resulta innegable que el mundo actual progresa impulsado por los datos. Como resultado, las organizaciones se ven inundadas de información procedente de una gran cantidad de fuentes. Con el objetivo de aprovechar al máximo el poder de estos datos surge el paradigma Modern Data Stack, un enfoque modular, escalable y distribuido para la gestión de datos. Pero, ¿qué es exactamente el Modern Data Stack?
En esencia, se trata de un conjunto de herramientas y tecnologías integradas diseñadas para optimizar los flujos de trabajo de datos, lo que permite a las organizaciones recopilar, procesar, almacenar y analizar de manera eficiente grandes cantidades de datos. Sin embargo, comprender el verdadero alcance de esta propuesta requiere analizar, al menos, los siguientes apartados:
- Qué hace que el Modern Data Stack sea único: Modularidad, escalabilidad y flexibilidad
- Rol protagonista de los flujos de datos (data pipelines): Cómo los flujos de trabajo robustos garantizan una integración y transformación de datos sin fisuras
- Procesos ETL vs ELT: Contrastar las metodologías tradicionales y modernas de procesamiento de datos
- Fundamentos del almacenamiento de datos: Principios clave como el modelado dimensional y el diseño de esquemas
- Gobernanza y seguridad: Mejores prácticas para garantizar la integridad, el cumplimiento y la confianza de los datos
- Herramientas y ecosistema: Un repaso a las herramientas más populares para la orquestación de flujos y el almacenamiento
- Tendencias emergentes: El futuro de los flujos de datos, data streaming y la automatización impulsada por la IA y la transmisión en tiempo real
Introducción a Modern Data Stack¶
La pila de datos moderna representa un cambio de paradigma en la forma en que manejamos los datos. A diferencia de las arquitecturas tradicionales y monolíticas, persigue la flexibilidad y la escalabilidad con un diseño modular que permite a las organizaciones elegir las mejores herramientas para cada etapa del ciclo de vida de los datos
En el centro de esta pila se encuentran los almacenes de datos que sirven como repositorio para el análisis de datos. Sin embargo, para alimentar este almacén, necesitamos transformaciones de datos robustas en procesos ETL/ELT eficientes. Es imperativo garantizar el flujo continuo de datos desde diversas fuentes hasta los almacenes donde se transforman y se preparan los datos para su análisis
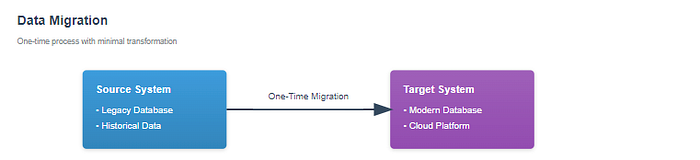
Data Migration¶
La migración de datos suele ser un proceso puntual o poco frecuente que consiste en trasladar datos de un sistema de almacenamiento a otro. Puede estar motivada por una actualización de la base de datos, el cambio a una nueva plataforma o la consolidación de fuentes de datos. El objetivo es transferir los datos con los mínimos cambios posibles, garantizando una transición fluida al nuevo sistema
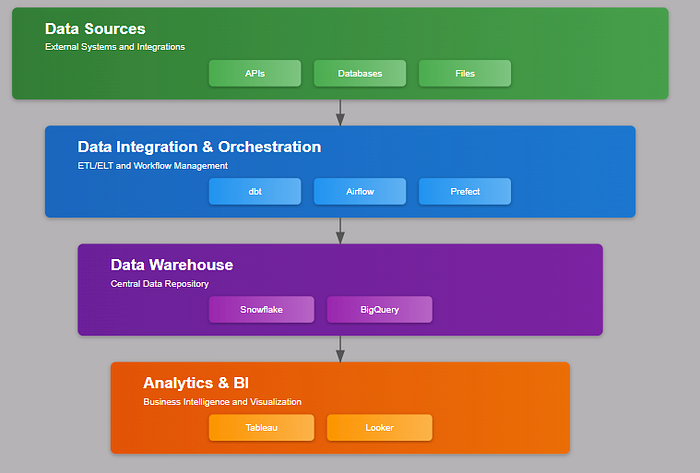
Arquitectura MDS¶
En el acelerado mundo actual, las decisiones se basan cada vez más en información en tiempo real o casi real. Para lograr agilidad es esencial contar con una pila de datos bien diseñada que tenga en consideración diferentes problemáticas:
- Data Integration: integración de datos desde fuentes múltiples y heterogéneas
- Data Transformation: procesos ETL/ELT que limpia, estandariza o enriquece datos
- Disponibilidad Analitica: los datos deben organizarse de manera que posibiliten los procesos de consulta (querying) y obtención de informes (reporting)
Antes de abordar la construcción de un MDS es preceptivo abordar los conceptos ETL (extraer, transformar, cargar) y ELT (extraer, cargar, transformar) a fin de comprender la diferencia con los procesos de migración de datos
Info
Siguiente: Sección Data Pipeline