Data Warehouse
Un Data Warehouse o almacén de datos empresariales (EDW) es una infraestructura fundamentalmente centralizada donde las empresas almacenan información valiosa, como datos de clientes y ventas, con fines analíticos y de elaboración de informes. Esto último es esencial pues el Data Warehouse tiene la finalidad principal de soportar la toma de decisiones a través de procesos de inteligencia empresarial (BI, Business Intelligence). Dichos procesos combinan datos actuales e históricos que se han extraído, transformado y cargado (ETL) de varias fuentes, incluidas las bases de datos internas del operacional así como otras externas. Normalmente, el Data Warehouse actúa como la única fuente de verdad (SSOT) de una empresa al centralizar los datos en un sistema no volátil y estandarizado accesible a los empleados pertinentes. Está, por ende, diseñado específicamente para facilitar el procesamiento analítico en línea OLAP así como el análisis rápido y eficiente de datos multidimensionales
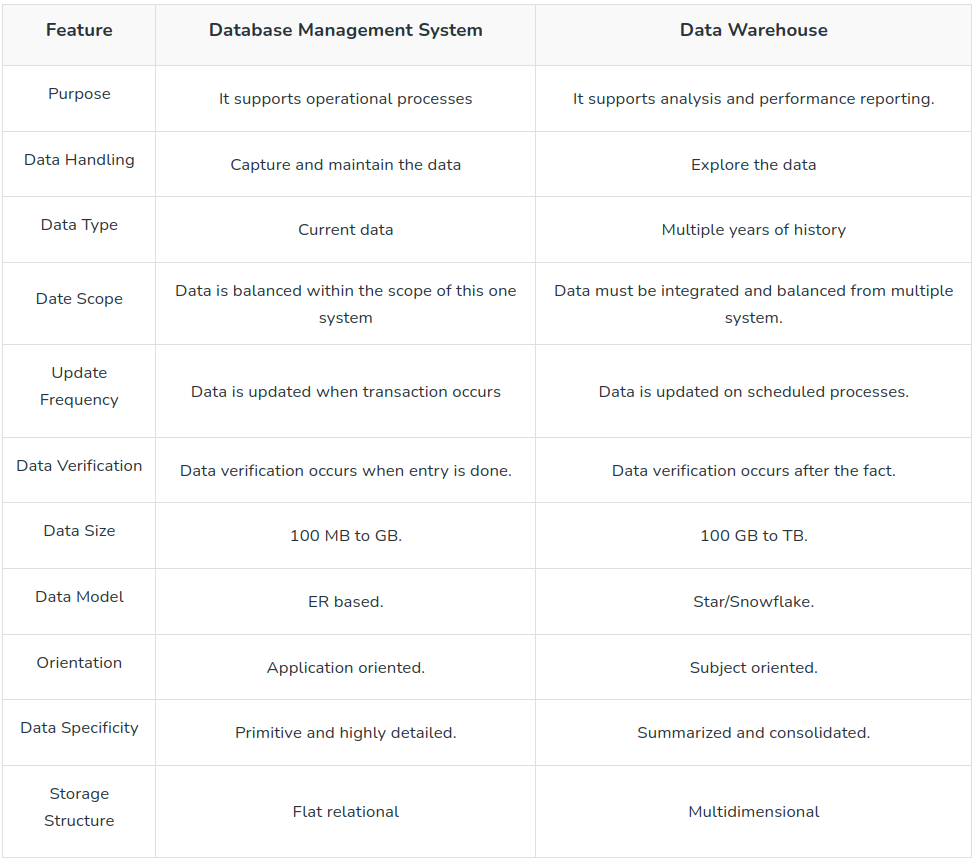
El Data Warehouse ha sido la columna vertebral de la analítica empresarial durante décadas, ofreciendo una gestión de datos fiable y estructurada. Sin embargo, a menudo deriva en problemas de coste, escalabilidad y agilidad. La aparición de los lagos de datos (Data Lake, Data Lakehouse) ha abordado algunas de estas limitaciones al proporcionar una solución de almacenamiento flexible y escalable para diversos tipos de datos. Al combinar el valor empresarial y el rendimiento de los almacenes de datos relacionales con la flexibilidad de los Data Lakes, las organizaciones pueden aprovechar los puntos fuertes de ambas tecnologías en una arquitectura de datos moderna
Integración of Data Lakes and Data Warehouses: Data Lakehouse¶
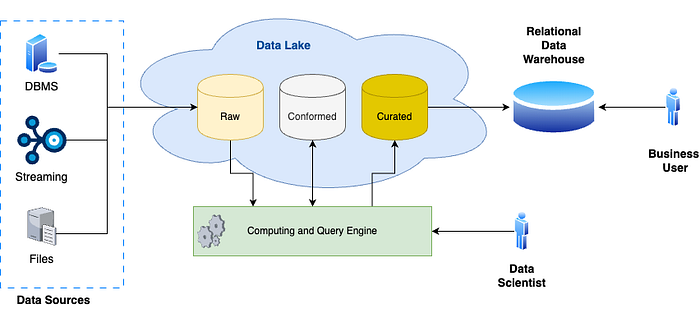
El Data Lake sustituye eficazmente a la zona de almacenamiento tradicional del almacén de datos. Junto con los procesos ETL clásicos desempeña un papel principal en los procesos de ingestión de datos, gestionando transformaciones de datos a gran escala, incluida la armonización de datos y la materialización de productos de datos. A continuación, los conjuntos de datos orientados al negocio se publican en un almacén de datos relacional, normalmente estructurado en un modelo dimensional, para dar soporte a las capacidades de elaboración de informes y de Business Intelligence (BI). Al mismo tiempo, el Data Lake puede utilizarse para la formación de modelos de aprendizaje automático (ML) y para soportar análisis avanzados
Ventajas de integrar el Data Lakehouse¶
- Versatilidad en el manejo de datos: Esta arquitectura puede gestionar eficazmente diversos formatos de datos, incluidos los datos estructurados, no estructurados y en flujo
- Rendimiento mejorado de informes y BI: El almacén de datos moderno ofrece un mejor rendimiento de consulta que los motores SQL y proporciona una mejor integración con las herramientas estándar de informes y BI.
- Escalabilidad: El desacoplamiento del almacenamiento y la computación permite gestionar volúmenes de datos crecientes sin problemas
- Análisis en tiempo real: permite a las empresas tomar decisiones oportunas basadas en los datos más actuales disponibles
- Reducción de costes: Al realizar transformaciones de datos dentro del Data Lake las organizaciones pueden reducir potencialmente los costes asociados al procesamiento de datos
- Mayor seguridad de los datos: Mejor control de la seguridad de los datos mediante mecanismos estándar de control de acceso basado en roles (RBAC)
Desventajas de integrar el Data Lakehouse¶
- Mayor complejidad: La naturaleza híbrida de esta arquitectura introduce una complejidad adicional, ya que requiere la orquestación de múltiples tecnologías. Para aprovechar todo el potencial de esta arquitectura se necesita un conjunto de habilidades especializadas y diversas, lo que podría dar lugar a problemas de contratación, mayores necesidades de formación y costes de mantenimiento más elevados
- Duplicación y gestión de datos: Aunque los costes de almacenamiento son relativamente bajos, la gestión de datos entre un Data Lake y un almacén de datos relacional puede resultar complicada. Esta arquitectura suele requerir cierto nivel de duplicación de datos, lo que puede complicar los esfuerzos de gobernanza y sincronización de datos. No aborda plenamente los retos críticos de la integración de datos, como la gestión de la complejidad de los datos, los metadatos y las reglas de mapeo contextual