Data Lakes
El concepto de Data Lakehouse fue introducido por el equipo de Databricks y popularizado posteriormente por Bill Inmon en su libro Building the Data Lakehouse. Hoy en día la idea ha sido ampliamente adoptada por los principales actores en la gestión de datos ya que la arquitectura combina la escalabilidad y la rentabilidad con la infraestructura analítica tradicionalmente asociada a los Data Warehouse. Este enfoque híbrido permite leer, procesar y comprender los datos de forma más eficiente, al tiempo que se aprovechan las soluciones de almacenamiento de bajo coste
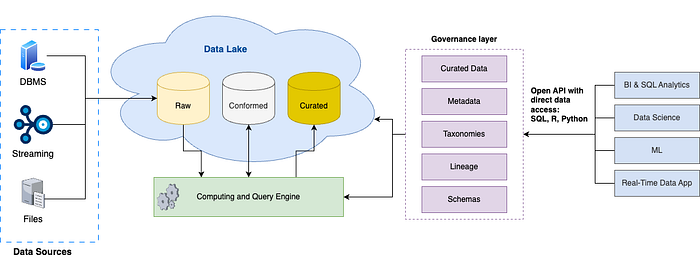
Principios del Data Lakehouse¶
- Aprovechar la infraestructura preexistente: siempre que sea posible, utilizar infraestructura existente y en opciones de almacenamiento de bajo coste como Amazon S3, Azure Blob Storage o Google Cloud Storage. Los datos deben almacenarse en formatos abiertos, como CSV, Parquet y ORC, para garantizar la compatibilidad y la flexibilidad
- Garantizar la coherencia de los datos con transacciones ACID: utilizar tecnologías para mantener la coherencia de los datos mediante transacciones ACID (atomicidad, coherencia, aislamiento y durabilidad) que a menudo se gestionan mediante SQL
- Admitir la aplicación y la evolución de esquemas: el Data Lakehouse debe admitir la aplicación y la evolución de esquemas, el uso de arquitecturas de esquemas de almacenes de datos como los esquemas en estrella y en copo de nieve
- Implementar mecanismos de gobernanza y auditoría: añadir funciones de gobernanza y auditoría incluido un control de acceso basado en roles muy detallado. Garantizar que la manipulación de datos se pueda realizar a través de diversas API (Scala, Java, Python, SQL) para cumplir con normativas como el RGPD y la CCPA
- Desacoplar el almacenamiento de la computación: la arquitectura debe permitir que los recursos de almacenamiento y computación se escalen de forma independiente dando cabida a más usuarios simultáneos y conjuntos de datos más grandes sin degradación del rendimiento
- Proporcionar acceso directo a los datos: ofrecer acceso directo a datos sin procesar, seleccionados y agregados para herramientas de inteligencia empresarial (BI). Esto reduce la obsolescencia de los datos, mejora su frescura, reduce la latencia y minimiza los costes de mantener copias separadas de los datos
- Admite API no SQL para el procesamiento de datos: incluye API declarativas eficientes y no SQL como las API de tipo DataFrame para permitir a los científicos de datos acceder directamente y procesar grandes volúmenes de datos, en particular para experimentos de aprendizaje automático que utilizan bibliotecas R y Python
- Adopción de formatos de datos abiertos y API: compatibilidad con formatos de datos abiertos y API que permiten el acceso directo a los datos sin depender de motores propietarios, lo que evita la dependencia de un proveedor y garantiza la flexibilidad a largo plazo
- Habilitación de la transmisión de datos y el análisis en línea: elimina la necesidad de sistemas separados para gestionar aplicaciones de datos en tiempo real
El concepto de Data Lakehouse parece más un esfuerzo pragmático por codificar el status quo existente que una arquitectura respaldada por un análisis coherente del problema. Dado que no se trata de un concepto innovador, la barrera para su adopción es baja y casi todos los proveedores afirman implementarlo. Aunque este concepto ha ganado un gran impulso, tiene ciertas limitaciones que pueden obstaculizar su eficacia:
- Enfoque centrado en la tecnología: el enfoque del Data Lakehouse se centra principalmente en soluciones tecnológicas, pasando por alto a menudo la importancia de las personas y los procesos en la gestión de datos. Las plataformas de datos eficaces requieren un enfoque holístico que integre la tecnología con las prácticas y la cultura de la organización
- Atención limitada a los silos de datos y la alineación empresarial: aunque el Data Lakehouse hace hincapié en la capacidad de descubrimiento de datos, tiende a descuidar los retos que plantean la eliminación de los silos de datos y la alineación de los activos de datos con los objetivos empresariales. También presta una atención insuficiente al ciclo de vida de los datos, los SLA (acuerdos de nivel de servicio) y los SLO (objetivos de nivel de servicio)
- Gobernanza centralizada frente a agilidad: la gobernanza centralizada y la aplicación de esquemas inherentes al Data Lakehouse pueden obstaculizar la agilidad de la organización. La rápida adaptación es fundamental a medida que las empresas evolucionan, y las estructuras de gobernanza rígidas pueden convertirse en un cuello de botella
- Abordaje inadecuado de los desafíos de la integración de datos: aunque el Data Lakehouse proporciona las capacidades técnicas para la transformación de datos a gran escala, no aborda completamente los desafíos críticos de la integración de datos, como la gestión de la complejidad de los datos, los metadatos y las reglas de mapeo de contexto. Estos son componentes esenciales para crear una plataforma de datos verdaderamente integrada y procesable