Data Pipelines
Los acrónimos ETL y ELT hacen referencia a los procesos de transformación responsables de alimentar el Data Warehouse con los datos desde las bases de datos del operacional

ETL¶
Se refiere al conjunto de procesos/aplicaciones en una organización diseñados para alimentar los almacenes de datos:
- Extract: Obtención de los datos desde múltiples fuentes (bases de datos, APIs, ficheros, etc.)
- Transform: Limpieza, validación, agregación y enriquecimiento de los datos
- Load: Escritura en el Data Warehouse de los datos una vez han sido transformados convenientemente
ELT¶
En aras de obtener una mayor escalabilidad en los almacenes de datos ha ganado popularidad la estrategia consistente en cargar primero los datos sin procesar y realizar las transformaciones dentro del propio almacén. Este cambio de orden es posible debido al aumento de la potencia computacional de los repositorios de datos

Tradicionalmente, el desarrollo y mantenimiento de las ETLs ha supuesto el reto más exigente para los departamentos de IT de las organizaciones. Ello es debido, fundamentalmente, a la trascendencia que tienen en los resultados de análisis que se obtienen finalmente así como a la diversidad y complejidad de las técnicas que intervienen. El grafo a continuación muestra de manera organizada algunas de estas técnicas
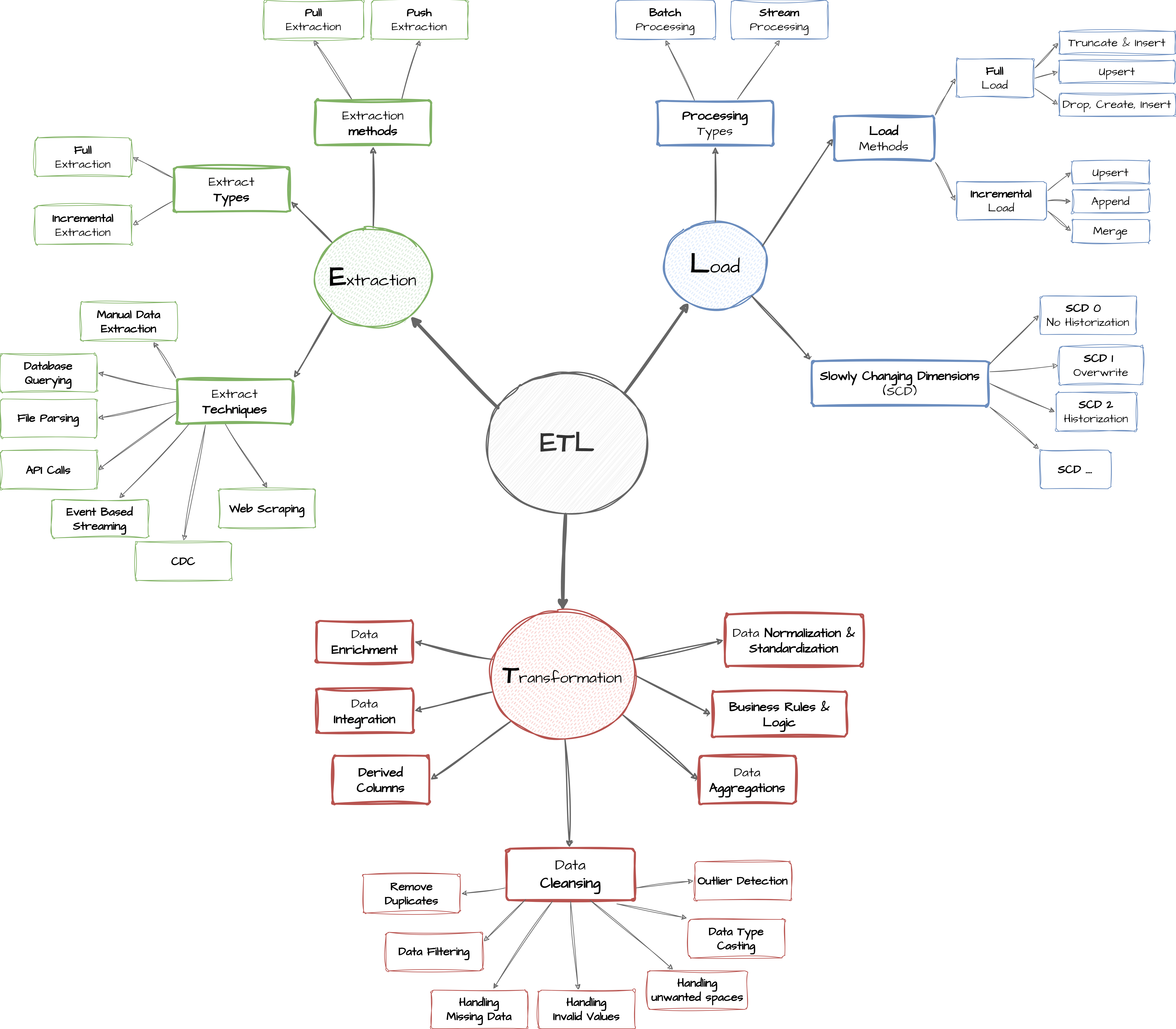
Es importante tener presente que ambos casos, tanto ETLs como ELTs, son casos particulares del más general concepto de data pipeline
Definición data pipeline¶
En términos muy sintéticos y sencillos, un data pipeline puede describirse como un mecanismo que transporta datos desde fuentes de datos hasta consumidores/almacenes de datos a través de algunos pasos intermedios que transforman y optimizan los datos en un formato que puede utilizarse para extraer conocimiento empresarial
| Data Pipeline clásico | Flujo de datos |
|---|---|
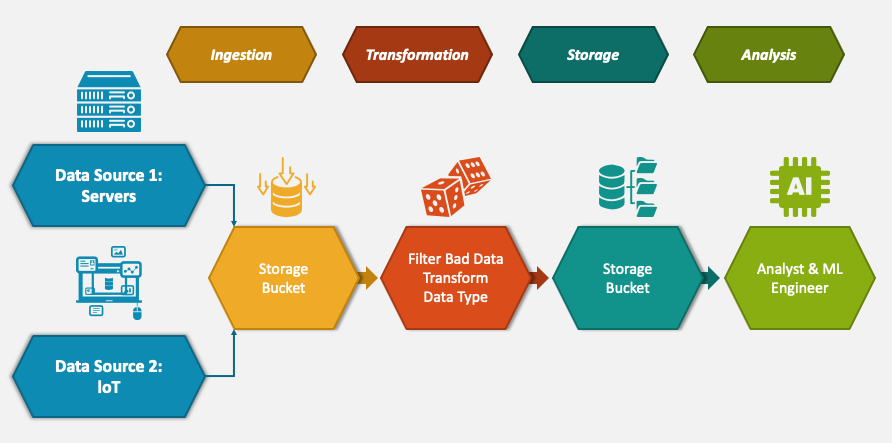 | 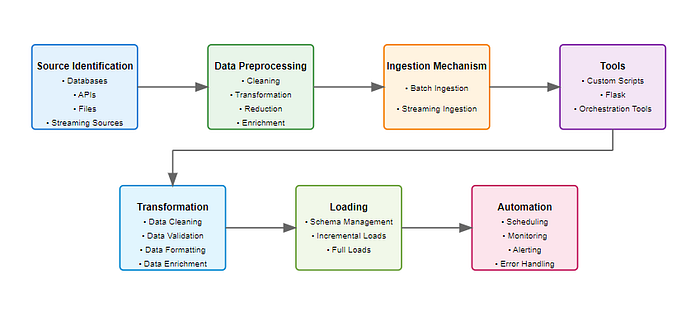 |
Tipos de data pipelines¶
Los data pipelines se pueden clasificar en dos tipos principales: procesamiento batch (discreto y/o por lotes) y streaming (procesamiento continuo/en tiempo real)
Batch pipelines¶
Caso típico del procesamiento de datos históricos que se utilizan en BI (Business Intelligence) para explorar, analizar y obtener información sobre actividades que han tenido lugar en el pasado. Por lo tanto, a menudo basta con el procesamiento por lotes tradicional en el que los datos se extraen, transforman y cargan periódicamente en un sistema de destino. Estos lotes pueden programarse para que se ejecuten automáticamente o pueden activarse mediante una consulta del usuario o una aplicación. El procesamiento por lotes permite realizar análisis complejos de grandes conjuntos de datos
Streaming pipelines¶
En muchos casos el análisis, la aplicación o el proceso empresarial requieren un flujo y una actualización continuos de los datos. En lugar de cargar los datos por lotes, los streaming pipelines mueven los datos de forma continua y en tiempo real desde el origen hasta el destino