Arquitectura
ClickHouse VLDB24
Publicación Proceedings VLDB Volume 17, Nº1 que ofrece una visión general de ClickHouse. Su capa de almacenamiento combina un formato de datos basado en los árboles tradicionales de fusión estructurados en forma de registro LSM (Log Structured Merge-Tree) con técnicas innovadoras para la transformación continua (por ejemplo, agregación, archivo de datos históricos) en segundo plano. Las consultas se escriben en un dialecto SQL y se procesan mediante un motor de ejecución de consultas vectorizado de última generación con compilación de código opcional. ClickHouse hace un uso intensivo de técnicas de poda para evitar evaluar datos irrelevantes en las consultas. Adicionalmente, es posible integrar otros sistemas de gestión de datos a nivel de función de tabla, motor de tabla o motor de base de datos
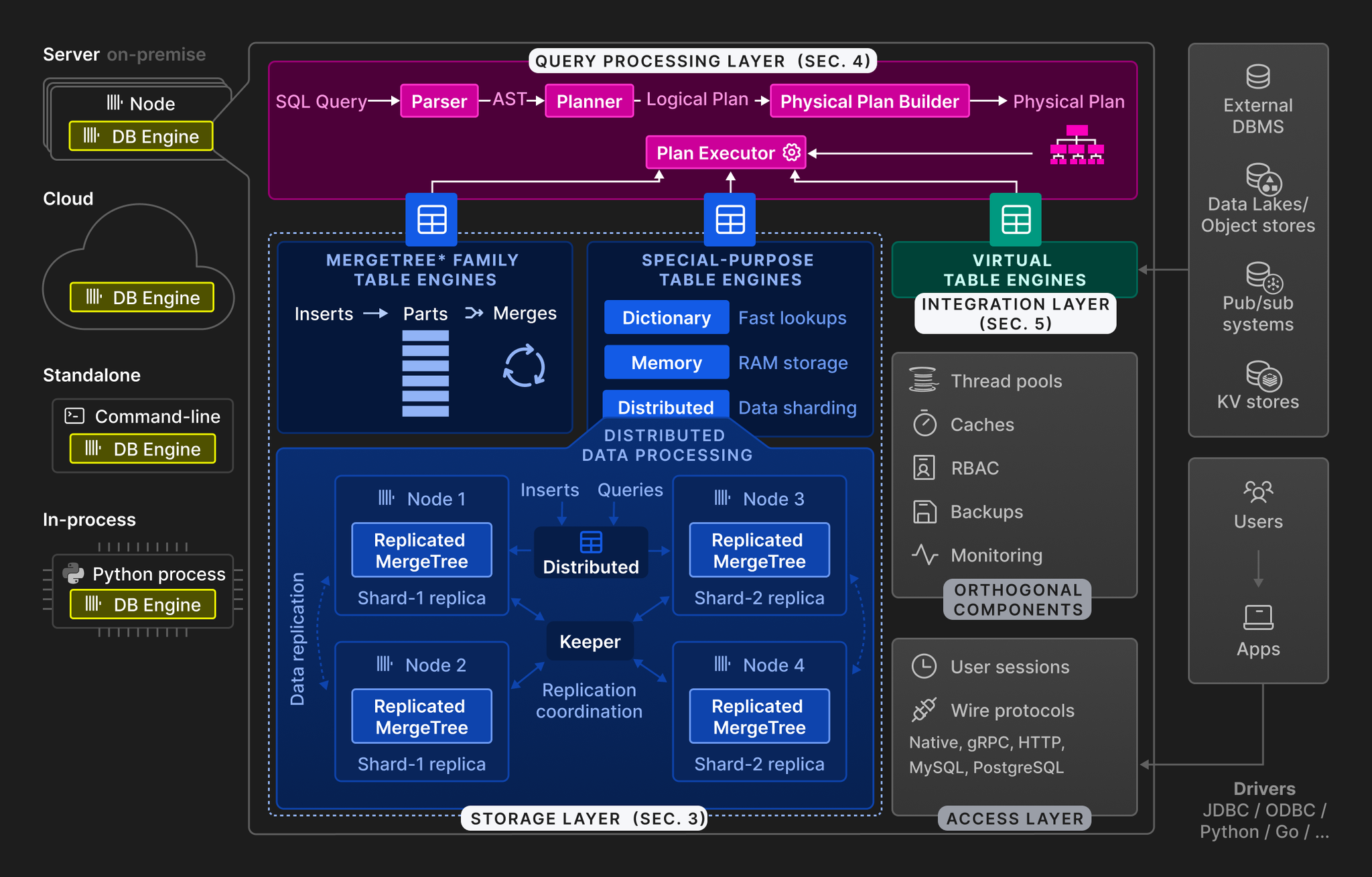
ClickHouse ha sido desarrollado en el lenguaje C++. En su arquitectura cabe distinguir tres bloques funcionales básicos:
- Procesamiento de consultas
- Almacenamiento de datos
- Capa de integración
Adicionalmente, una capa de acceso gestiona las sesiones de los usuarios y permite la comunicación a través de diversos protocolos. Más allá de estas capas principales, ClickHouse incluye componentes para el manejo de subprocesos, el almacenamiento en caché, el control de acceso basado en roles, las copias de seguridad y la supervisión continua
Procesamiento de Interrogaciones¶
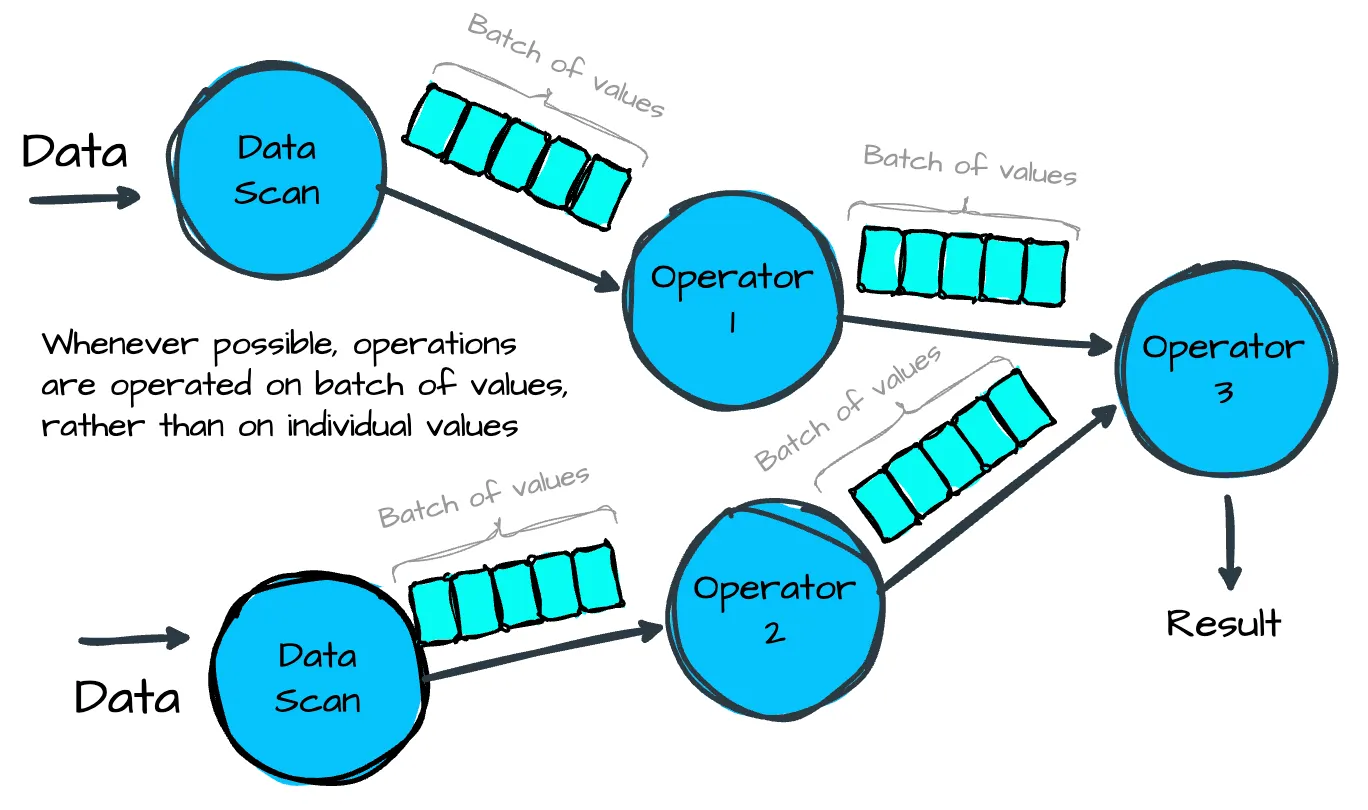
La capa de procesamiento de consultas analiza las consultas entrantes, creando y optimizando los planes de consulta lógicos y físicos, así como su ejecución. ClickHouse utiliza un modelo de ejecución vectorizada (como DuckDB, BigQuery o Snowflake) en combinación con la compilación oportunista de código
| Modelo Vectorizado | Ejecución Masivamente Paralela |
|---|---|
 | 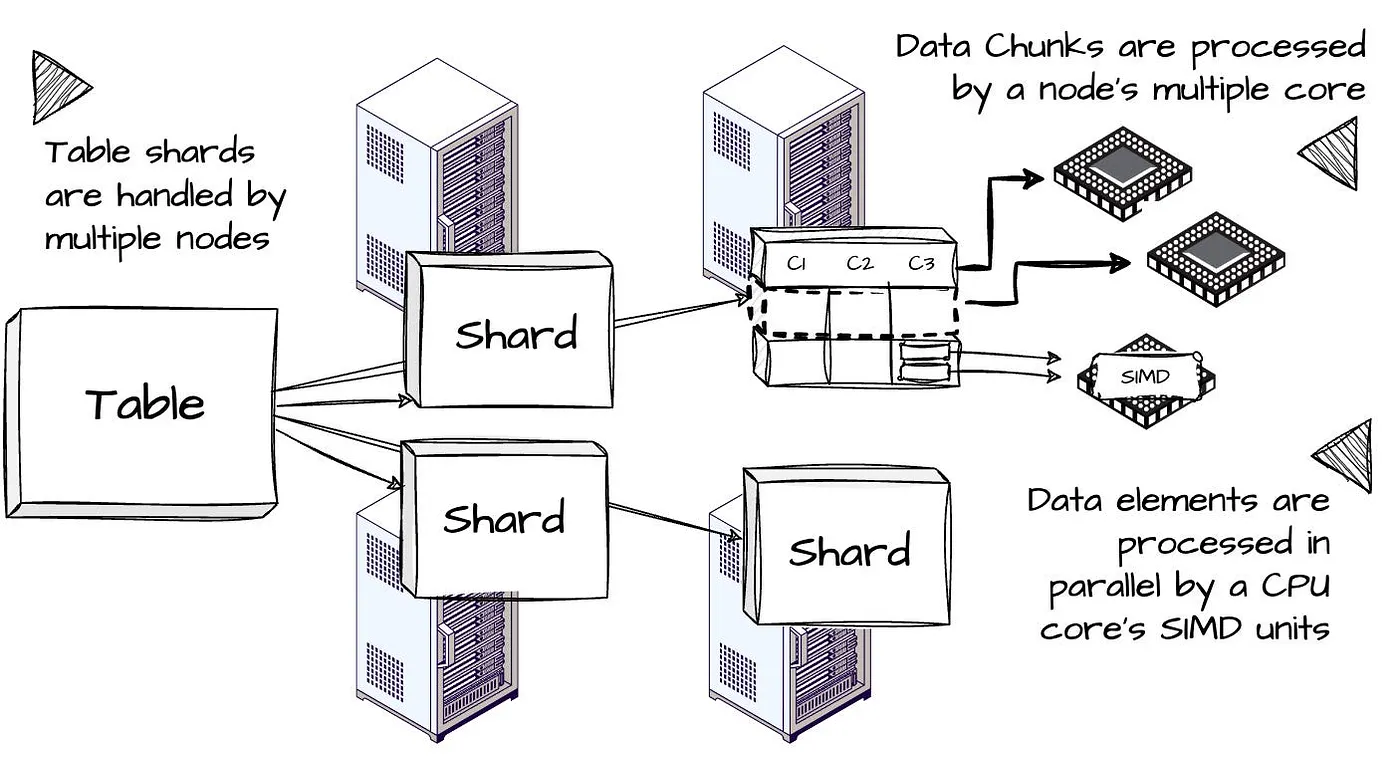 |
| El paralelismo en el procesamiento de consultas en ClickHouse se extiende a múltiples niveles: conjuntos de trabajo (data elements o working sets), vectores de datos (data chunks) y fragmentos (table shard) de tabla: |
- Fragmentos de tabla (table shards): ClickHouse es un sistema en cluster o multinodo. Las tablas pueden almacenarse fragmentadas entre varios nodos de manera que pueden escanear los fragmentos al mismo tiempo. Gracias a ello, se aprovechan al máximo todos los recursos de hardware y el procesamiento de consultas se puede escalar horizontalmente añadiendo nodos y, verticalmente, añadiendo núcleos en cada nodo
- Bloques de datos (data elements o working sets): en cada nodo, el motor de consultas ejecuta operadores simultáneamente en múltiples subprocesos. ClickHouse utiliza el modelo de vectorización para que los operadores generen, intercambien y consuman múltiples filas (bloques de datos) en lugar de filas individuales, con el fin de minimizar la sobrecarga de las llamadas a funciones virtuales
- Elementos de datos (data chunks): utilizando procesadores SIMD (Single Instruction, Multiple Data) cada operador puede procesar simultáneamente múltiples elementos de datos (ClickHouse VLDB2024)
Almacenamiento de Datos (Storage Layer)¶
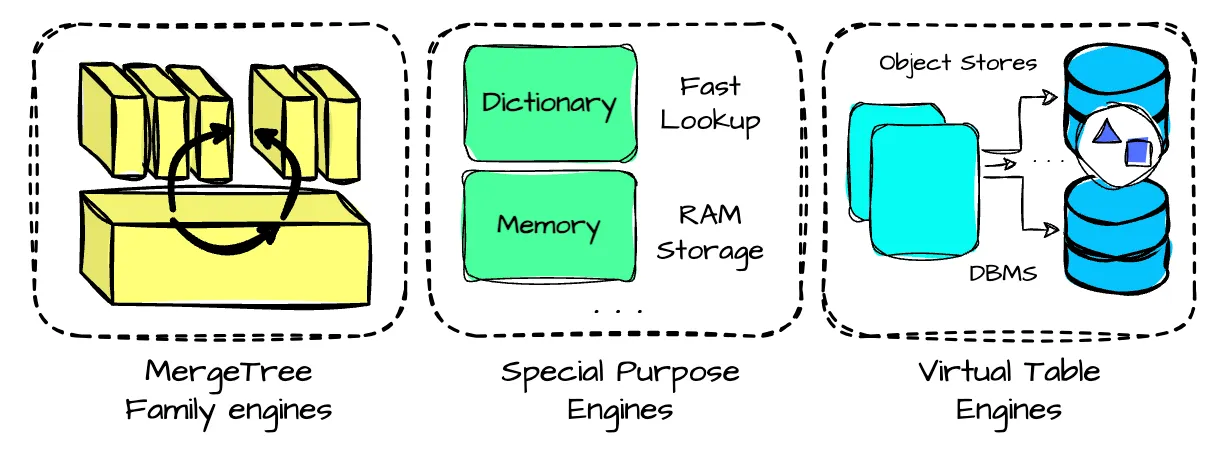
ClickHouse eleva a otro nivel el concepto de motor de almacenamiento (Storage Engine). En primer término, es preceptivo distinguir entre motores de tabla (Table Engines) y de base de datos (Database Engines). Cada uno de ellos ha sido diseñado para gestionar datos en función de distintos casos de uso y requisitos. En una primera aproximación, los engines se pueden agrupar en tres categorías:
- La primera categoría es la familia MergeTree: basado en los árboles LSM, las tablas se dividen en grupos de filas (particionado horizontal) ordenadas que, posteriormente, se fusionan de forma continua mediante un proceso en segundo plano. Cada motor de la familia MergeTree difiere en la forma en que fusiona las filas (ver Modelo de Ejecución y Estados de Agregación). Por ejemplo, las filas pueden agregarse (con AggregatingMergeTree) o sustituirse (con ReplacingMergeTree)
ClickHouse Storage Engines
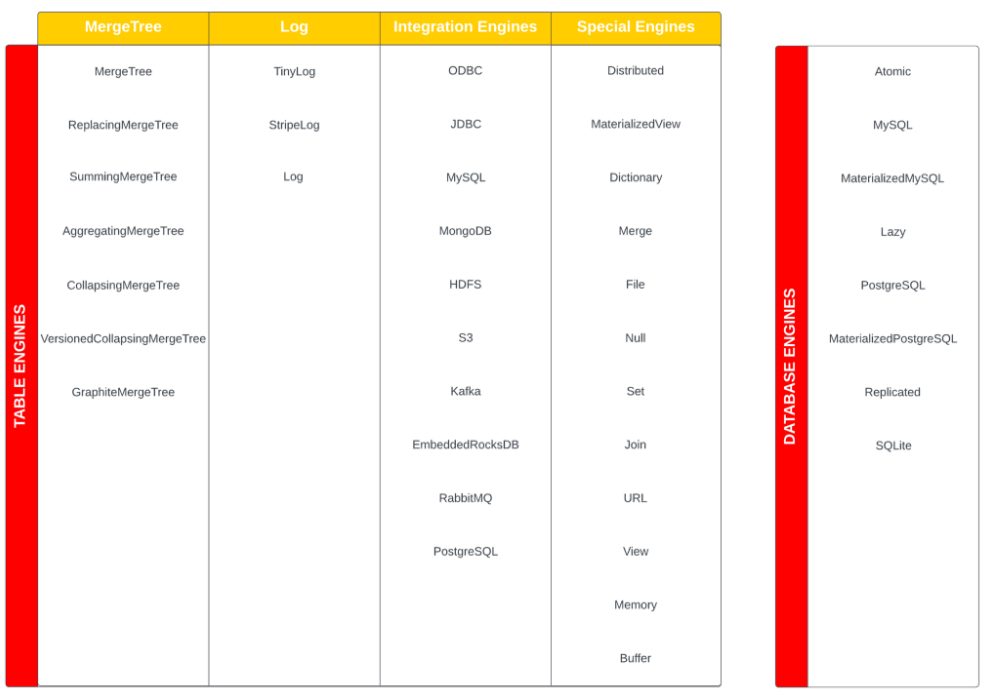
- La segunda categoría incluye motores de tablas de propósito específico diseñados para acelerar o distribuir la ejecución de consultas. Esta categoría incluye motores de tablas clave-valor en memoria denominados diccionarios que almacenan en caché los resultados de consultas ejecutadas periódicamente sobre fuentes de datos internas o externas
- La tercera categoría son los motores para el intercambio de datos con sistemas externos como bases de datos relacionales (PostgreSQL, MySQL, JDBC), documentales (MongoDB), sistemas de publicación/suscripción (Kafka) o almacenes de clave/valor (Redis). Estos motores también pueden trabajar con datos OTF (Iceberg, DeltaLake, or Hudi) o servicios de almacenamiento en la nube (AWS S3 MinIO, Google GCS)
Nivel de Integración¶
Si bien la problemática de integración está inherentemente resuelta en el apartado precedente, dado que la integración de otros sistemas de gestión de datos es un requisito funcional básico en ClickHouse merece un tratamiento por separado.
Esencialmente, existen dos enfoques para incorporar datos externos a una base de datos OLAP:
- Enfoque basado en push: un componente de terceros envía los datos desde fuentes externas a la base de datos
- Enfoque basado en pull: la base de datos se conecta a fuentes de datos remotas y extrae los datos del sistema. Este último es el método de integración utilizado en ClickHouse
Asimismo, los mecanismos de integración se agrupan en tres niveles:
- Nivel de función de tabla (Table Functions)
- Nivel de motor de tabla (Table Engines)
- Nivel de motor de base de datos (Database Engines)
En ClickHouse existen más de 50 funciones de tabla y motores para la conectividad con sistemas externos y ubicaciones de almacenamiento, más de 90 formatos de datos, incluyendo CSV, JSON, Parquet, Avro, ORC, Arrow y Protobuf. En el caso concreto de Parquet, como ocurre en DuckDB, el optimizador de consultas se sirve de las estadísticas de Parquet incrustadas como metadatos para evaluar los filtros directamente sobre los datos
Por último, la compatibilidad es máxima resultado de las interfaces de protocolo de comunicación compatibles con MySQL o PostgreSQL lo cual resulta de gran valor para permitir el acceso desde aplicaciones en las que los proveedores aún no han implementado conectividad nativa con ClickHouse